签名模仿检测 一种高级分析方法
在我之前的文章中,我以通用方式讨论了欺诈领域的高级分析应用程序。在本文中,我将深入研究欺诈签名伪造的特定领域的细节。难怪机构和企业将签名视为验证交易的主要方式。
人们签署支票、授权文件和合同、验证信用卡交易并通过签名验证活动。随着签名文件的数量及其可用性的大幅增加,签名欺诈的增长也在增加。
根据最近的研究,仅支票欺诈每年就会使银行损失约 9 亿美元,其中 22% 的欺诈支票归因于签名模仿欺诈。显然,美国每年有超过 275 亿张支票(根据 2010 年美联储支付研究),在每天处理的数亿张支票上将签名与人工进行直观比较证明是不切实际的。
大数据、基于 Hadoop 的分布式平台(如 MapR)的出现,使得经济高效地存储和处理大量签名图像成为可能。这使企业能够使用全面的历史交易数据,通过开发算法来发现签名模仿的模式,从而使传统的视觉比较自动化。
签名的艺术和科学:
在介绍自动签名验证类型和详细方法之前,让我们先了解一些与签名过程相关的概念以及一些流行的神话、签名伪造的类型,以及静态签名图像常规视觉比较的漏洞。
误区:同一个人的真实签名在所有交易中都完全相同
现实:签署签名的物理行为需要协调大脑、眼睛、手臂、手指、肌肉和神经。考虑到所有因素,难怪人们不会每次都签上完全相同的名字:某些元素可能会被省略或更改。个性、情绪状态、健康、年龄、个体签名的条件、签名可用的空间和许多其他因素都会影响签名之间的偏差。
签名伪造的类型:
在现实生活中,签名伪造是伪造者主要关注准确性而不是流畅性的事件。
签名伪造的范围分为以下三类:
1. 随机/盲目模仿伪造——通常与真实签名几乎没有相似性。当伪造者无法访问真实签名时,就会创建这种类型的模仿伪造。
2.不熟练的临摹伪造:签名被追踪,在下面的纸张上显示为一个微弱的压痕。然后可以将该缩进用作签名的指南。
3. 熟练的伪造 – 由可以访问一个或多个真实签名样本并经过大量练习可以模仿的者制作。熟练的伪造是所有伪造中最难验证的。

一个有效的签名验证系统必须能够通过可靠的定制算法检测所有这些类型的伪造。
手动验证难题:
由于主观决定,并在很大程度上取决于人为因素,如专业、疲劳、情绪、工作条件等,人工验证更容易出错和不一致,在熟练伪造(离线方法)的情况下会导致以下情况:
1:错误拒绝:错误地标记欺诈性交易(当它们没有被拒绝时),对客户满意度产生负面影响,通常称为 I 类错误。
2:虚假接受:运营商接受的真实签名和熟练伪造作为真实签名,导致财务和声誉损失,通常称为 II 型错误。

准确验证系统的目标是最大限度地减少这两种类型的错误。
签名特征:
让我们了解人工文件审查员区分欺诈和真实的签名特征。以下是用于签名验证的静态和动态特征的非详尽列表:
· 手迹不稳(静态)
· 提笔(动态)
· 修饰痕迹(静态和动态)
· 字母比例(静态)
· 签名形状/尺寸(静态)
· 倾斜/角度(静态)
· 两个或多个签名之间非常接近的相似性(静态)
· 速度(动态)
· 笔压(动态)
· 压力变化模式(动态)
· 加速模式(动态)
· 曲线平滑度(静态)
根据验证环境和样本采集条件,并非所有特征都可用于分析
自动签名验证系统的类型:
正如根据可行(可用)签名特征提取和业务/功能需求所讨论的那样,市场上广泛存在两类签名验证系统。
1: 离线签名验证:部署在无法监控个人实时签名活动的地方。在检查签名纸质文档的应用程序中,只有静态的二维图像可用于验证。由于明显的原因在这种类型的验证引擎中,动态特性。为了解决这些重要信息的丢失并产生高度准确的签名比较结果,离线签名验证系统必须模仿人类法医文件审查员使用的方法和方法。这种方法严重依赖于繁琐的图像预处理(图像缩放、调整大小、裁剪、旋转、过滤、定向梯度直方图阈值保持、哈希标记等)和熟练的机器学习技能。这里主要用到的功能,
虽然有很多限制,但在现实生活中,大多数支票交易和数字文档验证签名都是预先执行的,没有实时签名监控范围来捕捉动态特征。
对于离线签名验证,机器学习任务可以进一步分类为 1)一般学习(与个人无关) – 通过将质疑的签名与每个已知签名以 1:1 的基础进行比较来执行验证任务,以及 2)特殊学习(即person-dependent) — 验证被质疑的签名是否在同一个人的多个真实签名之间的变化范围内。
2:在线签名验证:签名是基于重复动作的反射动作,而不是刻意控制肌肉,甚至准确的伪造品比真正的签名需要更长的时间。顾名思义,在这种类型的验证系统中,捕捉速度、加速度和压力等关键动态特征是可行的。这种类型的系统更准确,因为即使对于复印机或专家来说,也几乎不可能模仿原始签名者的独特行为模式和特征。
实验简介:
让我们在模拟环境中讨论一个简单的离线验证解决方案。对于这项研究,数据是由 40 个人准备的,每个人贡献 25 个签名,从而拥有 1000 个真实签名。然后随机选择受试者伪造另一个人的签名,每个人 15 个,因此有 600 个(体面的欺诈过度抽样)伪造。现在有 25 个真实签名/人和 12 个伪造签名/人,数据被随机拆分为训练(75%)和验证(25%)数据,确保至少 15 个真实签名/人.in 训练数据。目标是建立一个具有个人独立学习方法的离线算法签名验证系统,用于确定来自验证的质疑签名是否属于特定个人的风格。

图:正版签名样本 图:个人样本(正版和伪造)
解决方案框架:
个人独立监督学习:将学习问题转换为二分类问题,其中输入包含一对签名之间的差异(相异性),并且根据似然比 (LR) 参考的似然比 (LR) 计算真实签名出现的几率来自好(真实)和坏(伪造)群体的合适的距离参数分布(配对签名的差异分数)。然后从一个人的真实签名中将一个被质疑的签名拟合到分布中以计算 LR 分数,并根据 LR 和预先指定的阈值(基于最大准确度),无论是否被质疑,都要做出分类决定签名(来自测试数据)对于特定的人来说是真实的。
模仿方程
在哪里
? P(Dg(i)|d) 是距离 d 处 Dg(genuine) 分布的概率密度函数值
? P(Db(i)|d) 是 Db(forged) 分布在距离 d 处的概率密度函数值
N 是一个人的已知样本数,用于 1:1 比较
? Ψ 是预先指定的阈值 >1
虽然建模任务很简单,但需要大量的图像预处理来计算基于提取的静态特征的签名对之间的距离/距离向量(d)。还需要合适的参数模型选择和具有最佳截止值的调整。
涉及的步骤:
1: 特征提取:这是一个技术含量很高的领域,涉及复杂的图像处理以提取特定人的区分元素和元素组合。
2:图像预处理和网格形成:每个签名经过灰度变换后经过椒盐噪声去除和倾斜归一化处理。然后经过适当的调整大小、裁剪和其他增强处理后,每张图像都用 4×7 网格重新构建
3:二进制特征向量提取:从像素图像网格和相应的局部直方图单元中提取GSC(梯度,结构和凹面)特征图,量化为1024位二进制特征向量(G,S和C特征的总和)。
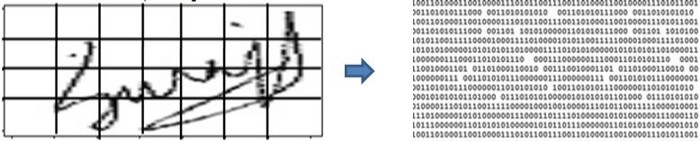
图:图像网格和 1024 位二进制特征向量
1:相似度(距离)度量:开发高斯地标(exp(-rij2/2σ2))集用于成对图像的点对点匹配,整体相似度或距离度量用于计算表示两个签名之间匹配强度的分数. 相似性度量将成对数据从特征空间转换为距离空间。一些。这里使用汉明距离方法。
(抱歉,由于篇幅限制,这里没有详细阐述这些主题,并将在单独的帖子中讨论。)
2:模型训练(分布拟合):这些训练数据的成对距离(d)分为两个向量,Dg-所有真实签名对之间的距离向量(样本真正来自同一个人)和Db-之间的距离向量所有伪造的签名对(样本来自不同的人)。这两个距离向量可以使用已知分布(例如高斯或伽马)进行建模。对于这个例子,伽马分布很好地拟合了数据。
3:似然比(LR)和分类决策:对于来自未标记数据(此处来自验证)的特定人的质疑签名,然后在上述预处理和距离得分??(成对相异)点之后与人的真实签名进行 1:1 匹配对拟合的密度曲线进行投影得到LR值-P(Dg|d)/P(Db|d)。如果似然比大于1,则分类决策是两个样本确实属于同一个人,如果比值小于1,属于不同的人。如果一个人总共有N个已知样本,那么对于一个有疑问的样本,可以进行N个1:1的验证,并乘以似然比。为方便起见,采用对数似然比 (LLR) 而不是似然比。
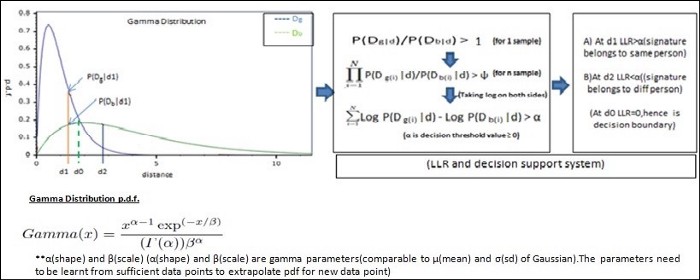
图:分布拟合和分类决策
性能评估:上述分布虽然有明显的重叠区域,但在区分两个区域(正版和欺诈)方面做得相当好。显然,决策边界由 LLR 的符号给出,修改后的决策边界可以是使用阈值 α 构造,使得 log P(Dg|d)?log P(Db|d) >α。定义为 [1-((错误接受+错误拒绝)/2)] 的模型准确度在特定的 α 值处最大。这涉及模型调整,对于指定数量的已知样本,α 的最佳设置表示为操作点。在 ROC 曲线中,使用不同数量的已知样本(从 12 到 15)生成,操作点显示为“*”。总体准确率约为 77%。
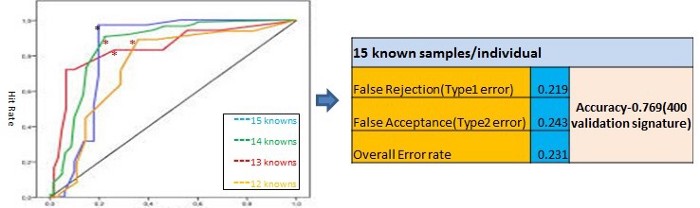
图:模型调整和性能
改进和前进的道路:
通过这个实验和简单的解决方案,实现了适度的准确性。然而,通过更大的训练数据、拟合和集成其他模型,包括非参数方法(深度学习、CNN 等),可以提高准确性。还结合图像对之间的其他距离测量(例如,Levenshtein 距离、倒角距离)作为附加特征和/或对这些不同特征进行简单/加权平均,将使不同测量更加稳健和可靠,从而为模型增加更多的辨别能力。
最后,尖端的签名验证系统需要具有适应性、敏捷性和准确性。这需要对不断增长的数据集进行深入分析并不断更新生产模型,以使效率随着时间的推移保持稳定,这与在人工操作的大批量情况下取得严证模仿签名的结果不同。
